Dataflow¶
Le dataflow est un outil pour visualiser rapidement vos étapes de traitement de données et vos sources de données.
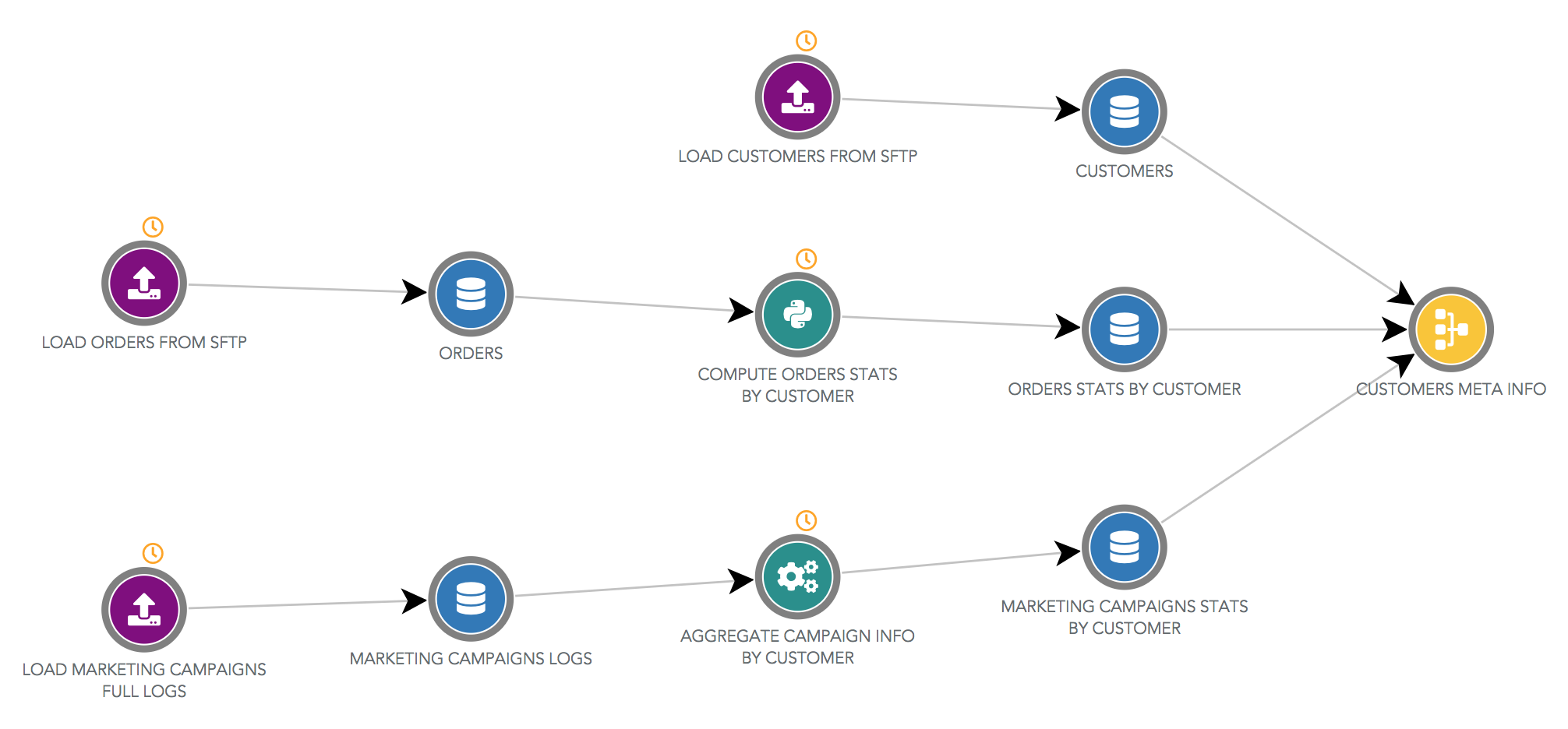
Edition des objets et dataflow
L'édition des datasources et des automations se fait toujours via leurs pages d'édition dédiées. Depuis le dataflow, si vous cliquez sur un objet, vous êtes redirigé vers sa page d'édition. Et depuis la page d'une source de données, vous pouvez revenir au dataflow, en n'affichant que les étapes utilisées pour construire cette source. Cela vous permet de naviguer très rapidement entre les composants de votre flux de données.
Sources de données¶
Les sources de données sont présentées dans des ronds bleus.
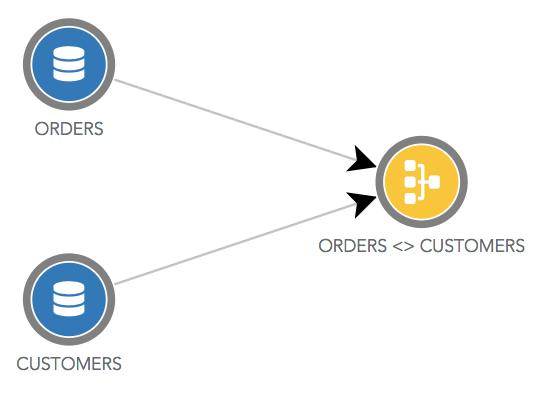
Il y a une exception pour les jointures qui sont dans des ronds jaunes. Dans le dataflow ci-dessous, la source de données "ORDERS <> CUSTOMERS" est une jointure entre la source "ORDERS" et la source "CUSTOMERS".
Automation¶
ETL Step¶
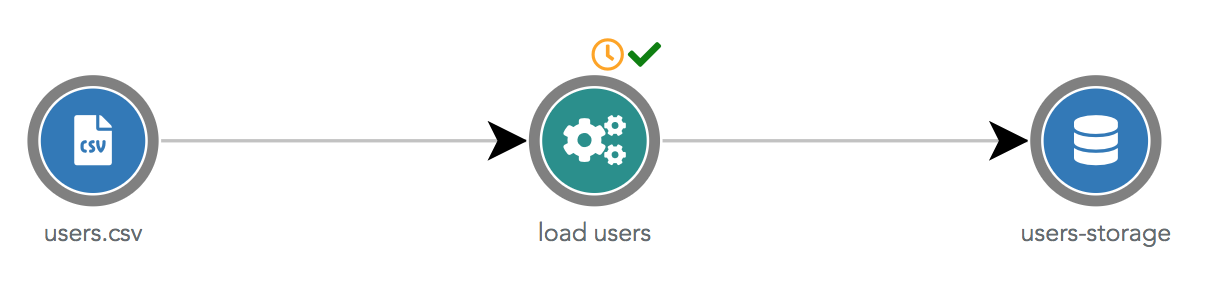
Les ELT Steps sont dans des ronds verts. Dans le dataflow ci-dessous, l'ETL Step "load users" utilise la datasource "users.csv" en entrée et envoie les données transformées dans la datasource "users-storage".
L'icône horloge orange indique que cette automation est schédulée (ou déclenchée par une chain-task qui est schédulée). L'icône verte indique que la dernière exécution du script est un succès (l'icône aurait été rouge en cas d'échec).
(S)FTP Import¶
Les imports (S)FTP sont dans des ronds violets. Une particularité est que ces automations n'ont qu'une datasource de sortie.

Python Script¶
Les scripts Python sont dans des ronds verts avec l'icône Python. Ils peuvent avoir autant de datasources d'entrées et
de sorties que souhaité. Pour apparaitre dans le dataflow, ces datasources d'entrées et sorties doivent avoir été
spécifiées manuellement dans l'onglet Utilisations de l'automation.
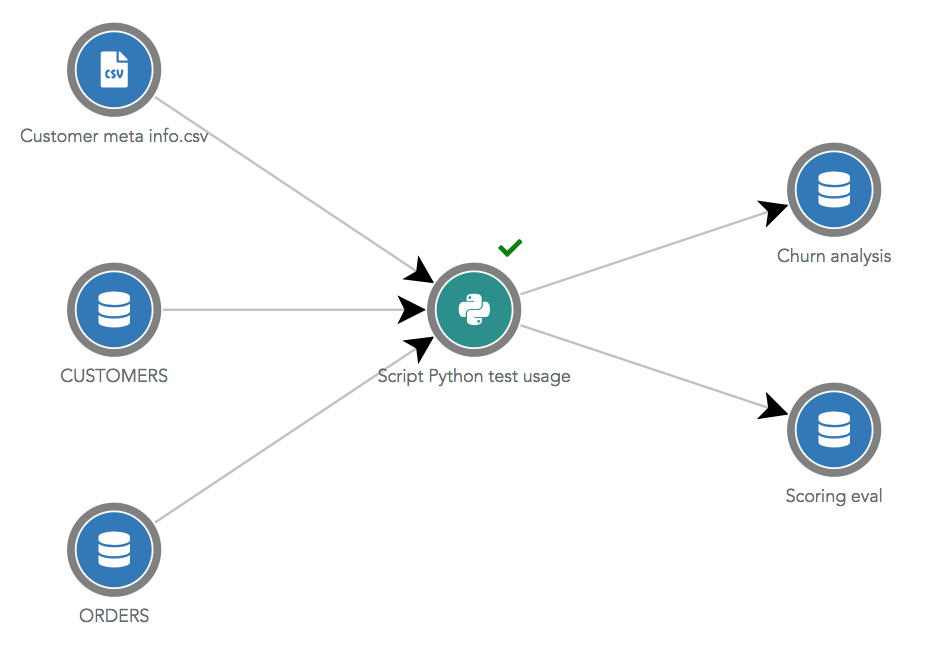
Spécifier les datasources d'entrées et de sorties de vos scripts Python est une bonne pratique !
Si ces sources ne sont pas spécifiées, leurs liens avec le script Python n'apparaitront pas dans le dataflow. Et si vous supprimez l'une de ces sources, même si elle est utilisée dans le script, Serenytics ne le détectera pas et autorisera cette suppression et le script sera cassé. En pratique, avant de supprimer une source, nous vérifions si son uuid apparaît dans le code d'un script Python. Si c'est le cas, la suppression sera refusée ( mais cela ne fonctionne pas si vous accédez à la source via son nom au lieu d'utiliser son uuid).
Filtrage du dataflow¶
Afficher seulement le dataflow schédulé¶
Par défaut, quand vous ouvrez le dataflow, seules les automations schédulées sont affichées (et leurs sources d'entrées et de sorties). Si une automation n'est pas schédulée, mais est déclenchée par une chain-task qui est schédulée, elle est aussi affichée. C'est aussi vrai si elle est déclenchée par une chain-task déclenchée elle-même par une autre chain-task schédulée et ainsi de suite).
Les datasources de type jointure qui ont une source enfant qui est modifiée par un traitement schédulé apparaissent aussi.
Afficher seulement le dataflow générant une Datasource¶
Depuis l'onglet Utilisations d'une source de données, vous pouvez cliquer sur le lien "Afficher le dataflow générant
cette source de données". Cela va ouvrir le dataflow en n'affichant que la partie qui est utilisée pour construire cette
source. Ce filtre apparait en haut à droite du dataflow et peut être supprimé.