Formules sur les sources de données¶
Quand vous ajoutez une formule sur une datasource, vous devez choisir son type parmi:
- formule simple
- formule conditionnelle
- formule valeur
Une formule simple ou une formule conditionnelle est une nouvelle colonne virtuelle ajoutée à votre source de
données. Vous pouvez l'utilisez comme une colonne normale, dans vos dashboards ou dans vos étapes de data-préparation.
Une formule valeur n'est pas une nouvelle colonne, mais une valeur unique calculée. Il s'agit souvent d'un
indicateur-clé que vous souhaitez afficher dans un tableau de bord (par exemple le nombre de ventes dans le mois en
cours).
Il est possible d'utiliser une formule dans une autre formule. Nous vous conseillons d'ailleurs de créer des formules simples et de les ré-utiliser au maximum. Cela vous permet de mieux vérifier les résultats de vos formules.
Exemples¶
Supposons que vos données contiennent une colonne [Prix], une colonne [Coût] et une colonne [Date]. Voici
quelques exemples de colonnes que vous pouvez créer.
Formules simples¶
- Calcul simple
[Prix] * 10
- Avec deux colonnes :
[Prix] / [Coût] * 100
- Avec des parenthèses :
([Prix] - [Coût]) / [Prix] * 100
- Opération sur une date :
extract_date_part([Date], "year")
Formules conditionnelles¶
- Condition IF :
[Prix] == 100
- Opérateur
and:
[Prix] > 10 and [Pays] != "USA"
- Opérateur
or:
[Prix] > 10 or [Coût] < 20
- Opérateur
in:
[Pays] in ("USA", "Allemagne", "France")
- Opérateur
not:
not ([Pays] in ("USA", "Allemagne", "France"))
- Dates :
[Date] > "2010-10-24" and [Date] < "2010-10-30"
- Parties de date :
extract_date_part([Date], "year") >= 2014
- Comparaison de chaînes de caractères :
like([code_postal], "_____")
Formules valeur¶
- Total simple:
sum([Prix])
- Total conditionnel :
sum_if([Prix], [Coût] > 10)
- Ratio :
sum_if([Prix], [Coût] > 10) / sum([Prix])
Formules de formules¶
Il est possible d'utiliser une formule dans une autre formule.
Par exemple, vous pouvez définir une formule de type Colonne simple, nommée "Produit GOLD" :
[Catégorie] in ["Bijouterie", "Montre", "Maroquinerie"]
et vous pouvez ensuite utiliser cette formule dans une seconde formule, par exemple pour calculer le revenu de ces "produits GOLD" dans le revenu total :
sum_if([Prix], [Produit GOLD]) / sum[Prix])
Utiliser des variables de dashboard dans une formule¶
Dans un dashboard, vous pouvez définir des variables dans le menu des options globales du dashboard :
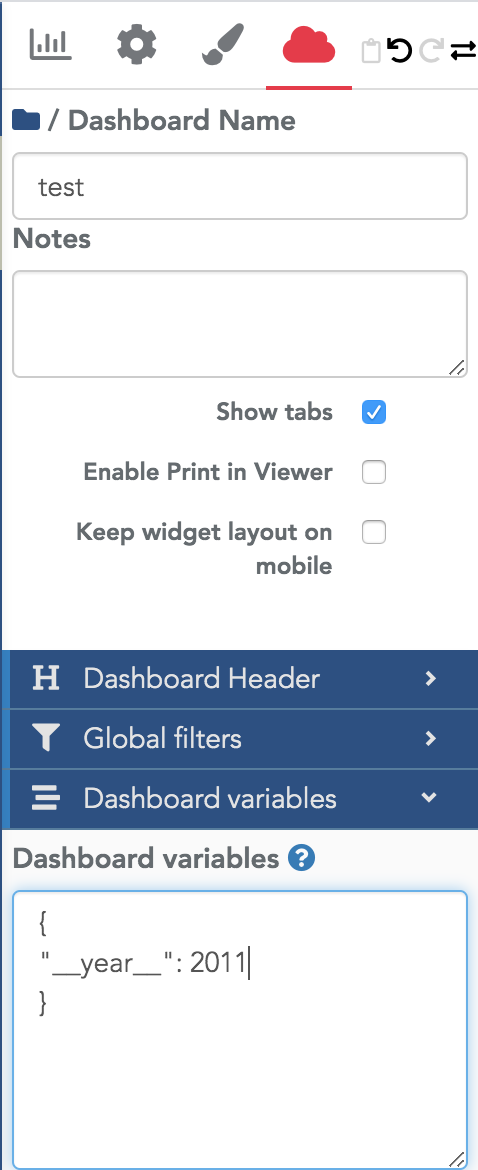
Ces variables peuvent ensuite être utilisées dans les formules des datasources (vous y avez accès avec la syntaxe
de double accolade {{myYear}}), par exemple :
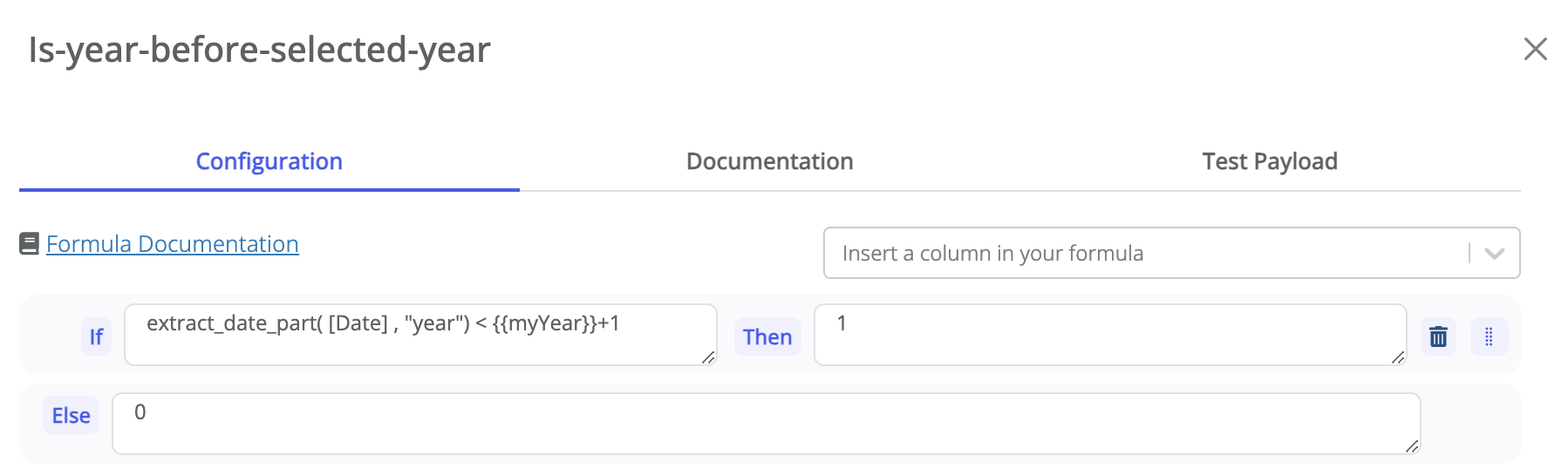
Voir ici pour plus de détails sur ce mécanisme.
Date et heure¶
extract_date_part()¶
Extrait une partie de la date ou de l'heure.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctiondate_part: choix parmi"year","month","quarter","week","day","dayofyear","weekday","hour"ou"minute".language[optional]: choix parmi"en","fr","num-fr","num-en". Utiliser cette option pour récupérer une valeur littérale au lieu d'une valeur numérique. Valable que sidate_partvaut"month"ou"weekday". Ajouter le préfixenumpermet de trier les données (par ex:01-Janvier,02-Février, ...).
Details:
- Pour
day: la fonction renvoie le numéro du jour dans le mois (eg. pour "2022-11-25", le résultat est 25). - Pour
dayofweek: la fonction renvoie le numéro du jour dans l'année (eg. pour "2022-2-25", le résultat est 56 car le 25 Février est le 56ème jour de l'année 2022). - Pour
weekday: lundi est le jour 0 et dimanche le jour 6. - Pour
week: une semaine commence le lundi. Tous les jours avant le premier lundi de l'année sont en semaine 0.
Exemple :
extract_date_part([MaColonne], "week")
Disponibilité : tout type de source de données.
first_day_of_week()¶
Extrait le premier jour de la semaine correspondant à une date.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
first_day_of_week([MaColonne])
Disponibilité : tout type de source de données (en SQL, seulement sur base PostGreSQL).
utc_to_timezone()¶
Convertit une colonne en UTC dans le fuseau horaire donné.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctiontimezone: un fuseau horaire valide (par ex. :"US/Eastern"ou"Europe/Paris"). Voir la liste complète.
Exemple :
utc_to_timezone([MaColonne], "Europe/Paris")
Disponibilité : tout type de source de données.
date_diff()¶
Calcule la différence entre 2 dates/heures dans l'unité de temps donnée. Le résultat est un entier.
Plus précisément, date_diff() détermine le nombre de frontières d'unités de temps qui sont traversées entre les deux
dates/heures. Le résultat est un entier (par ex: 1 pour la différence en jours entre "2016-10-15 23:00:00" et
"2016-10-16 03:00:00").
Paramètres :
first_date: colonne, autre formule ou résultat d'une fonctionsecond_date: colonne, autre formule ou résultat d'une fonctiontime_unit[optional]: une unité de temps valide. Par défaut :"day". Choix parmi :"year","month","day","hour","minute","second".
Exemple :
date_diff([MaColonneDate1], [MaColonneDate2], "hour")
Disponibilité : seulement MySQL, SQL Server, Redshift et le storage Serenytics (seulement de type AWS Redshift, non
disponible sur datawarehouse de type PostGreSQL). Sur MySQL, la seule unité de temps disponible est la valeur par
défaut : "day".
time_delta()¶
Calcule la différence entre 2 dates/heures dans l'unité de temps donnée. Le résultat est un flottant (par ex: 1.083 pour la différence entre "2016-10-15 14:00:00" et "2016-10-16 16:00:00").
Paramètres :
first_date: colonne, autre formule ou résultat d'une fonctionsecond_date: colonne, autre formule ou résultat d'une fonctiontime_unit[optional]: une unité de temps valide. Par défaut :"day". Choix parmi :"day","hour","minute","second".
Exemple :
time_delta([MyDateColumn1], [MyDateColumn2], "hour")
Disponibilité : tout type de source de données.
now()¶
Renvoie la date et l'heure actuelle (en UTC).
Disponibilité : tout type de source de données.
date()¶
Crée une date à partir de l'année, du mois et du jour.
Paramètres :
year: colonne, autre formule ou résultat d'une fonction.month[optional]: colonne, autre formule ou résultat d'une fonction qui renvoie le mois de la date à créer. Par défaut vaut 1 (janvier).day[optional]: colonne, autre formule ou résultat d'une fonction qui renvoie le jour de la date à créer. Par défaut vaut 1 (premier jour du mois).
Exemple :
date([ColonneAnnée], [ColonneMois])
Disponibilité : Tout type de source de données sauf Microsoft SQL Server.
date_add()¶
Ajoute un interval de temps à une date.
Paramètres :
myDate: colonne, autre formule ou résultat d'une fonction.interval_type: Unité de l'interval:"day","hour","minute"ou"second".nb_intervals: Nombre d'unités à ajouter à la date. Retranche les unités si négatif.
Exemple :
# to add 10 days to a given date
date_add([myDate], "day", 10)
Availability: Tout type de sources de données. Sur fichiers et APIs, seul "day" est accepté.
Filtrage sur les dates/heures¶
Pour les mesures de type date/heure, vous pouvez utiliser des fonctions dédiées pour calculer les conditions.
Exemples¶
Si vos données contiennent une colonne [Timestamp], vous pouvez la filtrer sur :
- aujourd'hui
[Timestamp] in day(0)
- hier
[Timestamp] in day(-1)
- les dernières 24 heures
[Timestamp] >= hour(-24)
- le mois courant
[Timestamp] In month(0)
- les 2 derniers mois en fenêtre glissante (= derniers 62 jours)
Timestamp] >= days(-62)
- le mois courant jusqu'à hier mais sans inclure aujourd'hui
[Timestamp] >= month(0) and [Timestamp] < day(0)
- l'année en cours jusqu'à hier inclus
[Timestamp] In year_to_date(0)
- l'année précédente jusqu'au même jour qu'aujourd'hui du mois précédent
[Timestamp] In month_to_date(-1)
Note sur les limites de périodes¶
timestamp <= period(arg)signifie tous les instants jusqu'à la fin de la période inclusetimestamp < period(arg)signifie tous les instants jusqu'à avant le début de la périodetimestamp >= period(arg)signifie tous les instants depuis le début de la période inclus-
timestamp > period(arg)signifie tous les instants depuis après la fin de la période -
period(0)signifie la période actuelle (ex. : aujourd'hui) -
period(-1)signifie la période pérécédente (ex. : hier), et ainsi de suite -
period_to_date(0)signifie la période actuelle jusqu'à hier inclus. Par exemple, pouryear_to_date(0), si la date du jour est2018-06-20, la période concernée démarre à2018-01-01 00:00:00et se termine à2018-06-19 23:59:59. period_to_date(-1)signifie la période précédente jusqu'au même jour qu'aujourd'hui l'année dernière. Par exemple, pouryear_to_date(-1), si la date du jour est2018-06-20, la période concernée démarre à2017-01-01 00:00:00et se termine à2017-06-19 23:59:59.
Fonctions disponibles¶
minute(arg)hour(arg)day(arg)week(arg)week_to_date(arg)month(arg)month_to_date(arg)quarter(arg)quarter_to_date(arg)year(arg)year_to_date(arg)
Chaînes de caractères¶
like()¶
Compare les valeurs d'une colonne avec un pattern. Le test est sensible à la casse (majuscule ou minuscule) sauf pour les datasources de type MySQL ou SQLServer où le test est insensible à la casse.
Pour être insensible à la casse sur toutes les bases, utiliser la fonction ilike.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionpattern: Pattern à valider. Peut contenir des caractères génériques (%valide zéro ou plusieurs caractères,_valide un seul caractère).
Exemple :
# retourne true si zip_code a une taille de 5 et commence par "75"
like([zip_code], "75___")
# retourne true si url contient la chaîne de caractères "/product/"
like([url], "%/product/%")
Disponibilité : tout type de source de données.
ilike()¶
Compare les valeurs d'une colonne avec un pattern, en étant insensible à la casse (majuscule ou minuscule).
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionpattern: Pattern à valider. Peut contenir des caractères génériques (%valide zéro ou plusieurs caractères,_valide un seul caractère).
Exemple :
# retourne true si zip_code a une taille de 5 et commence par "75"
ilike([zip_code], "75___")
# retourne true si url contient la chaîne de caractères "/product/" ou "/PRODUCT/"
ilike([url], "%/product/%")
Disponibilité : tout type de source de données.
contains()¶
Renvoie vrai si une chaîne de texte contient une sous-chaine de texte. Le test est sensible à la casse (majuscule ou minuscule) sauf pour les datasources de type MySQL ou SQLServer où le test est insensible à la casse.
Pour être insensible à la casse sur toutes les bases, utiliser la fonction icontains.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionsubstring: Chaîne de texte à chercher.
Exemple :
# retourne true si zip_code contient "75"
contains([zip_code], "75")
# retourne true si url contient la chaîne de caractères "/product/"
contains([url], "/product/")
Disponibilité : tout type de source de données.
icontains()¶
Renvoie vrai si une chaîne de texte contient une sous-chaine de texte. Le test est toujours insensible à la casse (majuscule ou minuscule).
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionsubstring: Chaîne de texte à chercher.
Exemple :
# retourne true si zip_code contient "75"
icontains([zip_code], "75")
# retourne true si url contient la chaîne de caractères "/product/" ou "/PRODUCT/"
icontains([url], "/product/")
Disponibilité : tout type de source de données.
regexp_match()¶
Renvoie True si une chaîne de caractères match une expression régulière, False sinon.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionpattern: Expression regulière à matcher.
# returns true if zip_code length is five and first two digits are "75" and last 3 digits are numbers
regexp_match([zip_code], "^75[0-9]{3}$")
# details:
# ^ matches the begining of the string
# 75 matches the string "75"
# [0-9] matches a decimal between 0 and 9
# {3} indicates that [0-9] must be matched exactly three times
# $ matches the end of the string
# returns true if a string is a date with format YYYY-MM-DD
regexp_match([date_str], "^[0-9]{4}-[0-9]{2}-[0-9]{2}$")
Disponibilité : tout type de source de données, sauf MS SQLServer.
left()¶
Retourne les n premiers caractères d'une chaîne de caractères.
Paramètres:
column: colonne, autre formule ou résultat d'une fonctionn: nombre de caractères à extraire
Exemple :
left([MyColumn], 5)
Disponibilité: tout type de source de données.
right()¶
Retourne les n derniers caractères d'une chaîne de caractères.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionn: nombre de caractères à extraire
Exemple :
right([MyColumn], 5)
Disponibilité : tout type de source de données.
str_len()¶
Retourne la taille d'une chaîne de caractères.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
str_len([MyColumn])
Disponibilité : tout type de source de données.
lower_case()¶
Renvoie column en minuscules.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
lower_case([MaColonne])
upper_case()¶
Renvoie column en majuscules.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
upper_case([MaColonne])
lpad()¶
Renvoie column en la complétant, du coté gauche, avec le caractère padding_char, pour atteindre la taille nb_chars.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionnb_chars: taille de la chaîne de caractères renvoyéepadding_char: caractère à utiliser pour compléter la chaîne
Exemple :
lpad([MaColonne], 4, "0")
rpad()¶
Renvoie column en la complétant, du coté droit, avec le caractère padding_char, pour atteindre la taille nb_chars.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionnb_chars: taille de la chaîne de caractères renvoyéepadding_char: caractère à utiliser pour compléter la chaîne
Exemple :
rpad([MaColonne], 4, " ")
split()¶
Découpe une chaîne sur le délimiteur donné et renvoie la partie à la position donnée.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctiondelimiter: délimiteurpart: position de la partie à renvoyer (en comptant à partir de 1).
Exemple :
split([MaColonne], "/", 2)
Disponibilité : tout type de source de données sauf Microsoft SQL Server.
substring()¶
Extrait une sous-chaîne de caractères.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionfirst_char: Index du premier caractère extrait. Commence à 1.nb_chars: Longueur de la sous-chaîne extraite
Exemple :
substring([MaColonneChaïneDeCaractères], 1, 5)
Disponibilité : tout type de source de données.
replace()¶
Remplace toutes les occurences d'une chaîne de caractères par une autre.
Parameters:
column: colonne, autre formule ou résultat d'une fonctionsubstring_from: Chaîne de caractères à remplacersubstring_to: Chaîne de caractères à utiliser en remplacement
Example:
replace([MyStringColumn], "ABC", "X")
Disponibilité : tout type de source de données.
Conversions¶
float()¶
Convertit une colonne de chaînes de caractères en float. Si la chaîne de caractères n'est pas une représentation
d'un float, la fonction renvoie une erreur. Dans ce cas, vous pouvez créer une fonction conditionnelle qui va tester
si le format de la chaîne de caractères est valide avec regexp_match([input_column],"[+-]?([0-9]*[.])?[0-9]+").
Si c'est le cas, vous pouvez retourner float([input_column]) sinon une valeur par default (null() ou 0).
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
float([MaColonneChaïneDeCaractères])
Disponibilité : toutes les sources exceptés les fichiers.
numeric()¶
Convertit une colonne de chaînes de caractères en valeurs numériques. Si la chaîne de caractères ne peut pas être convertie en valeur numérique, le résultat est 0.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
numeric([MaColonneChaïneDeCaractères])
Disponibilité : seulement les fichiers.
str()¶
Convertit les valeurs d'une colonne en chaînes de caractères.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
str([MaColonne])
Disponibilité : tout type de source de données.
round()¶
Retourne l'entier le plus proche. Par exemple round(3.1) est 3 et round(3.9) est 4.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
round([MaColonne])
Disponibilité: tout type de source de données.
to_int()¶
Convertit les valeurs d'une colonne en entier. Les nombres flottants sont convertis en entier. Les valeurs non définies sont converties en zéro.
to_int retourne le plus grand entier inférieur à la valeur en entrée. Utilisez la fonction round pour arrondir à
l'entier le plus proche.
Renvoie 0 si la valeur en entrée est NULL.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
to_int([MaColonne])
Disponibilité: tout type de source de données.
datetime_from_string()¶
Convertit une chaîne de caractères en date.
Cette fonction va retourner une erreur si une seule des lignes n'a pas le format passé en paramètre. Si vous n'êtes
pas sûr de la qualité de vos données, utilisez la fonction regexp_match pour vérifier le format de chaque ligne.
Si une ligne n'est pas au bon format, retournez null() au lieu de datetime_from_string.
Paramètres:
string: colonne, autre formule ou résultat d'une fonction.format: format de la chaîne de caractères à convertir. Si votre datasource est un fichier, utilisez le format de date Python (voir la documentation strftime.org). Si votre datasource est une table PostGreSQL ou un storage Serenytics, utilisez le format PostGreSQL (voir la documentation postgresql.org. Si votre datasource est une table MySQL, utilisez la syntax MYSQL (voir la documentation dev.mysql.com). Si votre datasource est une table BigQuery, utilisez la syntaxe BigQuery (voir la documentation cloud.google.com).
Exemple:
Dans cet exemple, la colonne à convertir contient des chaînes de caractères du type: 2013--01--23 21:17
# pour un fichier
datetime_from_string([date_str], "%Y--%m--%d %H:%M")
# pour une table PostGreSQL ou un storage Serenytics
datetime_from_string([date_str], "YYYY--MM--DD HH24:MI")
# pour une table MySQL
datetime_from_string([date_str], "%Y--%m--%d %H:%i")
Availability: Tout type de source de données sauf Microsoft SQL Server.
json_extract_path_text()¶
Extrait une valeur dans une chaîne de caractères JSON en spécifiant son chemin dans le JSON. Renvoie la chaîne de texte vide si le chemin n'existe pas dans le JSON.
Paramètres :
string: colonne, autre formule ou résultat d'une fonction.path1: première clé du chemin pour accéder à la valeur cherchée dans le JSON[path2]: seconde clé du chemin pour accéder à la valeur cherchée dans le JSON- jusqu'à 5 clés
Availability : Uniquement les sources de type Storage, Redshift PostGreSQL et MySQL.
Exemple :
# si la valeur dans la colonne est '{"first_name":"john", "last_name": "doe"}', renvoie 'john'.
json_extract_path_text([json_str], "fist_name")
# si la valeur dans la colonne est '{"first_name":"john", "last_name": "doe", "address": {"city" : "paris"}}'
# renvoie 'paris'.
json_extract_path_text([date_str], "address", "city")
# si la valeur dans la colonne est '{"first_name":"john", "last_name": "doe", "address": {"city" : "paris"}}'
# renvoie la chaine de texte vide.
json_extract_path_text([date_str], "address", "zipcode")
Rang¶
is_first()¶
Renvoie 1 si la valeur courante apparaît pour la première fois dans la colonne, 0 sinon. Peut être utilisé pour travailler avec des valeurs uniques ou supprimer des doublons.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
is_first([MaColonne])
Disponibilité : seulement les fichiers.
ntile()¶
Trie les lignes en fonction de la colonne passée en argument puis les range dans nb_buckets groupes qui ont tous le
même nombre de lignes. Renvoie l'index du groupe dans lequel est rangée la ligne. Le premier groupe qui contient les
plus petites valeurs a l'index 1.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionnb_buckets: nombre de groupes à utiliser
Exemple :
ntile([MaColonne], 100)
Disponibilité : tout type de source de données.
rank()¶
Trie les lignes en fonction de la colonne passée en argument puis renvoie le rang de chaque ligne. Si plusieurs lignes
ont la même valeur, elles ont le même rang et il y aura une discontinuité dans les résultats.
Si partition_by est défini, le rang est indépendant pour chaque valeur de cette colonne.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionorder: soit"asc"(croissant) soit"desc"(décroissant)partition_by[optional]: colonne, autre formule ou résultat d'une fonction
Exemple :
rank([MaColonne], "asc")
# calcule le rang des commandes pour chaque client
rank([commande.date], "asc", [commande.id_client])
Disponibilité : tout type de source de données.
dense_rank()¶
Trie les lignes en fonction de la colonne passée en argument dans l'ordre croissant ou décroissant, et renvoie le rang
de chaque ligne. Si plusieurs lignes ont la même valeur, elles ont le même rang mais contrairement à la fonction rank,
il n'y aura pas de discontinuité dans les résultats.
Si partition_by est défini, le rang est indépendant pour chaque valeur de cette colonne.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionorder: soit"asc"(croissant) soit"desc"(décroissant)partition_by[optional]: colonne, autre formule ou résultat d'une fonction
Exemple :
dense_rank([MaColonne], "desc")
# calcule le rang des commandes pour chaque client
rank([commande.date], "asc", [commande.id_client])
Disponibilité : tout type de source de données.
Valeurs¶
sum()¶
Calcule la somme.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
sum([MaColonne])
sum_if()¶
Calcule la somme pour les lignes qui satisfont une condition.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctioncondition: expression booléenne
Exemple :
sum_if([MaColonne], [MonAutreColonne] == 3)
avg(), avg_if()¶
Renvoie la moyenne. Voir sum et sum_if pour plus de détails.
min(), min_if()¶
Renvoie le minimum. Voir sum et sum_if pour plus de détails.
max(), max_if()¶
Renvoie le maximum. Voir sum et sum_if pour plus de détails.
count(), count_if()¶
Renvoie le nombre de lignes des données. Voir sum et sum_if pour plus de détails.
dcount(), dcount_if()¶
Renvoie le nombre de lignes distinctes. Voir sum et sum_if pour plus de détails.
last_value()¶
Renvoie la dernière valeur de la colonne value_column en triant de manière croissante par la colonne order_column.
Paramètres :
value_column: colonne, autre formule ou résultat d'une fonctionorder_column: colonne, autre formule ou résultat d'une fonction utilisée pour trier les valeurs devalue_column
Exemple :
# obtiens la dernière valeur dans une série temporelle
last_value([valeur], [date])
last_value_if()¶
Renvoie la dernière valeur de la colonne value_column pour les lignes qui satisfont la condition, en triant de
manière croissante par la colonne order_column.
Paramètres :
value_column: colonne, autre formule ou résultat d'une fonctionorder_column: colonne, autre formule ou résultat d'une fonction utilisée pour trier les valeurs devalue_columncondition: expression booléenne
Exemple :
# obtiens la valeur à la fin du mois précédent
last_value([valeur], [date], [date] in month(-1))
quantile()¶
Renvoie la valeur de la colonne à la valeur du quantile fournie en argument (fraction).
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionfraction: valeur du quantile désirée (par ex. 0.5 pour la médiane)interpolation: méthode d'interpolation à utiliser quand le quantile désiré se situe entre 2 points. Choix parmi :"linear"(linéaire) ou"nearest"(plus proche valeur dans les données).
Exemple :
# calcule la médiane :
quantile_if([MaColonne], 0.5, "linear")
Disponibilité : tout type de source de données sauf MySQL. Sur une base PostGreSQL, la colonne doit avoir un type float (et non int).
quantile_if()¶
Renvoie la valeur de la colonne à la valeur du quantile fournie en argument (fraction), mais avec la condition
indiquée.
Paramètres :
column: colonne, autre formule ou résultat d'une fonctionfraction: valeur du quantile désirée (par ex. 0.5 pour la médiane)interpolation: méthode d'interpolation à utiliser quand le quantile désiré se situe entre 2 points. Choix parmi :"linear"(linéaire) ou"nearest"(plus proche valeur dans les données).condition: condition à appliquer avant le calcul
Exemple :
# calcule la médiane :
quantile([MaColonne], 0.5, "linear", [other_col]=="PROD")
Disponibilité : seulement fichiers et API.
Fonctions de qualité de données¶
is_defined()¶
Renvoie False si la valeur de la colonne est NULL ou une chaîne de caractères vide, sinon renvoie True.
Utilisez not is_defined([myCol]) pour tester si une colonne est non NULL.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
is_defined([MaColonne])
is_defined() dans une formule conditionnelle dans une data-source de type SQLServer
Pour une data-source de type SQLServer, il faut utiliser la fonction is_defined_sqlserver_condition([MaColonne])
dans une formule conditionnelle, à la place de is_defined([MaColonne]).
is_empty()¶
Renvoie True si la colonne est une chaîne de caractères vide, sinon renvoie False. La colonne doit être de type
String. Utilisez not is_empty([myCol]) pour tester si une colonne est non vide.
Paramètres :
column: colonne, autre formule ou résultat d'une fonction
Exemple :
is_empty([MaColonne])
Autres formules¶
null()¶
Renvoie NULL.
Cette fonction peut être utilisée quand vous souhaitez compter les valeurs distinctes (dcount) d'une colonne en excluant
certaines lignes. Pour cela, vous pouvez créer une formule qui renvoie null() pour les lignes à exclure. Cela
fonctionne car les lignes à NULL ne sont pas comptées par un dcount.
Pour tester si une colonne est NULL ou est une chaine de texte vide, utilisez les fonctions is_defined ou
is_empty.
Exemple :
A partir d'une table contenant une liste d'achats de clients, vous pouvez compter le nombre de clients qui ont fait des achats avec un prix supérieur à 100 (en utilisant la formule ci-dessous). Cela fonctionnera aussi si vous groupez selon une ou plusieurs dimensions (par exemple pour créer une table avec le nombre de clients qui ont fait des achats, ceux qui ont fait des achats de plus de 100€, groupés par pays et par catégorie de produits).
IF [price]>100 THEN [client_id]
ELSE null()