Data source formulas¶
When you add a formula on a datasource, you must choose its type among:
- simple column
- conditional column
- value
A simple column or a conditional column is a new "virtual" column which is added to your datasource.
Then, you can use this formula exactly like a standard column of your datasource, in your dashboards or in your data
preparation steps.
A value is not a new column, it is a single computed value (usually a single KPI such as the number of sales in
the current month).
It is possible to use a formula within another formula. We advise you to create small and simple formulas and then to combine them. This makes it easier to check the results of your formulas.
Examples¶
Let's say your data contains a column [Price], a column [Cost] and a column [Date]. Here are some examples of what
new columns you can create.
Simple formulas¶
- Simple calculus
[Price] * 10
- Using two columns:
[Price] / [Cost] * 100
- With parentheses:
([Price] - [Cost]) / [Price] * 100
- Operation on Date
extract_date_part([Date], "year")
Conditional formulas¶
- Simple IF condition:
[Price] == 100
- Using and operator:
[Price] > 10 and [Country] != "USA"
- Using or operator:
[Price] > 10 or [Cost] < 20
- Using in operator
[Country] in ("USA", "Germany", "France")
- Using not operator
not ([Country] in ("USA", "Germany", "France"))
- Using full dates:
[Date] > "2010-10-24" and [Date] < "2010-10-30"
- Using date parts:
extract_date_part([Date], "year") >= 2014
- Using string comparison:
like([postal_code], "_____")
Value formulas¶
- Simple total:
sum([Price])
- Conditional total:
sum_if([Price], [Cost] > 10)
- Ratio:
sum_if([Price], [Cost] > 10) / sum([Price])
Formulas of formulas¶
You can use a formula within another formula. As an example, you can create a simple formula named "GOLD Product":
[Category] in ["Jewelry", "Watch", "Leather goods"]
and then use it in a second formula to compute the ratio of the revenue of these GOLD products within the total revenue:
sum_if([Price], [GOLD Product]) / sum[Price])
Using dashboard variables in a formula¶
In a dashboard, you can define dashboard variables in the global dashboard options menu:
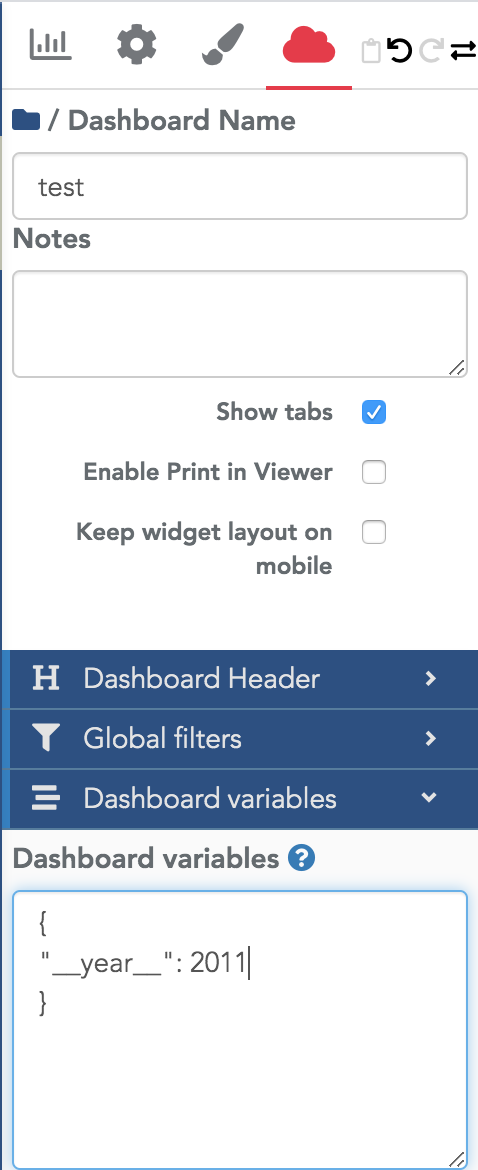
These variables can be used in datasource formulas. The value of a variable can be retrieved with the double bracket
syntax {{__myVar__}}. Here is an example:
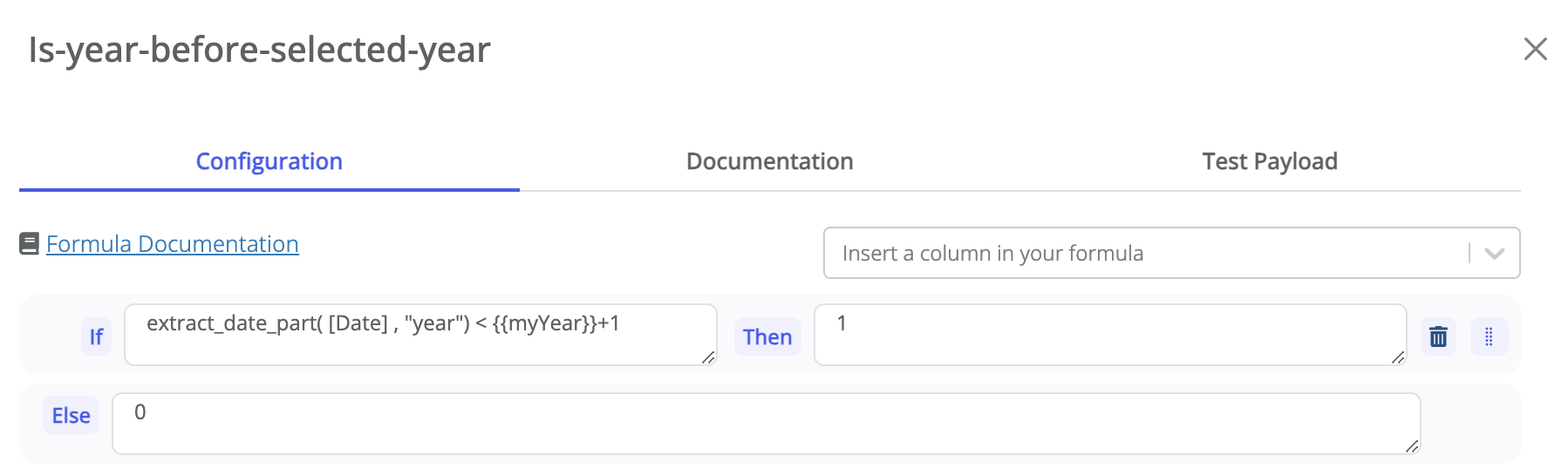
See here for more details about using variables in datasource formulas.
Date-time functions¶
extract_date_part()¶
Extract date part of a datetime column.
Parameters:
column: column, formula or functiondate_part: can be"year","month","quarter","week","day","dayofyear","weekday","hour"or"minute".language[optional]: can be"en","fr","num-fr","num-en". Use this option to get a literal value instead of a numerical value (valid only formonthandweekday). Using thenumprefix makes the data sortable (e.g. 01-January, 02-February, ...).
Details:
- For
day: the function returns the day of the month (eg. for "2022-11-25", it returns 25). - For
dayofweek: the function returns the day rank since the beginning of the year (eg. for "2022-2-25", it returns 56 as the 25th of February if the 56th days of the year 2022). - For
weekday: monday is day 0 and sunday is day 6. - For
week: a week starts the monday. Days before the first monday of the year are in week 0.
Example:
extract_date_part([MyColumn], "week")
Availability: all data source types.
first_day_of_week()¶
Extract the first day of a week.
Parameters :
column: column, formula or function
Example :
first_day_of_week([MyColumn])
Availability : all data types (in SQL, only available on PostGreSQL servers).
utc_to_timezone()¶
Convert a column in UTC to the specified timezone.
Parameters:
column: column, formula or functiontimezone: a valid timezone such as"US/Eastern"or"Europe/Paris". See full list.
Example:
utc_to_timezone([MyColumn], "Europe/Paris")
Availability: all data source types.
date_diff()¶
Return difference between 2 date-times in specified time unit. The result is an integer.
More precisely, date_diff() determines the number of unit of time boundaries that are crossed between the two
datetimes. The result is an integer (e.g.: 1 for the difference in days between "2016-10-15 23:00:00" and
"2016-10-16 03:00:00").
Parameters:
first_date: column, formula or functionsecond_date: column, formula or functiontime_unit[optional]: a valid time unit. Default:"day". It can be one of:"year","month","day","hour","minute","second".
Example:
date_diff([MyDateColumn1], [MyDateColumn2], "hour")
Availability: only MySQL, SQL Server, AWS Redshift and AWS Redshift Storage. On MySQL, the only time_unit
available is the default one: "day".
time_delta()¶
Return difference between 2 date-times in specified time unit. The result is a float: e.g. 1.083 for the delta between "2016-10-15 14:00:00" and "2016-10-16 16:00:00"
Parameters:
first_date: column, formula or functionsecond_date: column, formula or functiontime_unit[optional]: a valid time unit. Default:"day". It can be one of:"day","hour","minute","second".
Example:
time_delta([MyDateColumn1], [MyDateColumn2], "hour")
Availability: All source types.
now()¶
Return current date-time (in UTC).
Availability: All source types.
date()¶
Create a date from year, month and day data.
Parameters:
year: column, formula or function that returns the year of the date to create.month[optional]: column, formula or function that returns the month of the date to create. Default: 1 (January).day[optional]: column, formula or function that returns the day of the date to create. Default: 1 (first day of the month).
Example:
date([YearColumn], [MonthColumn])
Availability: All source types except Microsoft SQL Server.
date_add()¶
Add a certain interval to a date.
Parameters:
myDate: column, formula or function containing the initial date.interval_type: type of interval to add. It can be one of:"day","hour","minute","second".nb_intervals: number of intervals to add. A negative value will substract the interval.
Example:
# to add 10 days to a given date
date_add([myDate], "day", 10)
Availability: All source types except. For files and APIs, only "day" is accepted.
Date-time filtering¶
For date/time columns, you can use special functions to compute conditions.
Examples¶
If your data contains a column [Timestamp], you can filter it on:
- today
[Timestamp] in day(0)
- yesterday
[Timestamp] in day(-1)
- last 24 hours
[Timestamp] >= hour(-24)
- current month
[Timestamp] In month(0)
- last 2 months with a rolling window (= last 62 days)
Timestamp] >= days(-62)
- current month until yesterday but not including today
[Timestamp] >= month(0) and [Timestamp] < day(0)
- current year to date (from first day of the year to yesterday included)
[Timestamp] In year_to_date(0)
- previous month to date (from first day of previous month to same day as today, last month)
[Timestamp] In month_to_date(-1)
Note on date/time data bounds¶
timestamp <= period(arg)means all timestamps until the end of the period includedtimestamp < period(arg)means all timestamps until before the beginning of the periodtimestamp >= period(arg)means all timestamps since the beginning of the period included-
timestamp > period(arg)means all timestamps since after the end of the period -
period(0)means the current period (e.g. today) -
period(-1)means the previous period (e.g. yesterday), and so on. -
period_to_date(0)means the current period until yesterday (included). Foryear_to_date(0), if today is2018-06-20, the range starts at2018-01-01 00:00:00and ends at2018-06-19 23:59:59 period_to_date(-1)means from first day of previous period to same day as today in previous period. Foryear_to_date(-1), if today is2018-06-20, the range starts at2017-01-01 00:00:00and ends at2017-06-19 23:59:59
Available functions¶
minute(arg)hour(arg)day(arg)week(arg)week_to_date(arg)month(arg)month_to_date(arg)quarter(arg)quarter_to_date(arg)year(arg)year_to_date(arg)
String functions¶
like()¶
Compares column values to a pattern. This function is case-sensitive for all the datasources (except for MySQL and SQLServer where it is case-insensitive).
Use ilike to be case-insensitive.
Parameters:
column: column, formula or functionpattern: Pattern to match. Can contain wildcards (%matches zero or more characters,_matches a single character).
Example:
# returns true if zip_code length is five and first two digits are "75"
like([zip_code], "75___")
# returns true if url contains the string "/product/"
like([url], "%/product/%")
Availability: all data source types.
ilike()¶
Compares column values to a pattern. This function is case-insensitive for all the datasources.
Parameters:
column: column, formula or functionpattern: Pattern to match. Can contain wildcards (%matches zero or more characters,_matches a single character).
Example:
# returns true if zip_code length is five and first two digits are "75"
ilike([zip_code], "75___")
# returns true if url contains the string "/product/" or "/PRODUCT/"
ilike([url], "%/product/%")
Availability: all data source types.
contains()¶
Searches a substring in a string. This function is case-sensitive for all the datasources (except for MySQL and SQLServer where it is case-insensitive).
Use icontains to be case-insensitive.
Parameters:
column: column, formula or functionsubstring: substring to search.
Example:
# returns true if zip_code length contains "75"
contains([zip_code], "75")
# returns true if url contains the string "product"
contains([url], "product")
Availability: all data source types.
icontains()¶
Searches a substring in a string. This function is case-insensitive for all the datasources.
Parameters:
column: column, formula or functionsubstring: substring to search.
Example:
# returns true if zip_code length is five and first two digits are "75"
icontains([zip_code], "75")
# returns true if url contains the string "product" or "PRODUCT"
icontains([url], "product")
Availability: all data source types.
regexp_match()¶
Returns True if a string matches a regular expression else returns False.
Parameters:
column: column, formula or function.pattern: Regular expression to match.
# returns true if zip_code length is five and first two digits are "75" and last 3 digits are numbers
regexp_match([zip_code], "^75[0-9]{3}$")
# details:
# ^ matches the begining of the string
# 75 matches the string "75"
# [0-9] matches a decimal between 0 and 9
# {3} indicates that [0-9] must be matched exactly three times
# $ matches the end of the string
# returns true if a string is a date with format YYYY-MM-DD
regexp_match([date_str], "^[0-9]{4}-[0-9]{2}-[0-9]{2}$")
Availability: all data sources types except MS SQLServer.
left()¶
Returns the n first characters of a string.
Parameters:
column: column, formula or functionn: number of characters to extract
Example:
left([MyColumn], 5)
Availability: all data source types.
right()¶
Returns the last n characters of a string.
Parameters:
column: column, formula or functionn: number of characters to extract
Example:
right([MyColumn], 5)
Availability: all data source types.
str_len()¶
Returns the length of a string.
Parameters:
column: column, formula or function
Example:
str_len([MyColumn])
Availability: all data source types.
lower_case()¶
Returns column formatted in lower case.
Parameters:
column: column, formula or function
Example:
lower_case([MyColumn])
Availability: all data source types.
upper_case()¶
Returns column formatted in upper case.
Parameters:
column: column, formula or function
Example:
upper_case([MyColumn])
Availability: all data source types.
lpad()¶
Returns column, left-padded to length nb_chars characters with padding_char, replicated as many times as
necessary.
Parameters:
column: column, formula or function to padnb_chars: length of output stringpadding_char: character to use for padding
Example:
lpad([MyColumn], 4, "0")
rpad()¶
Returns column, right-padded to length nb_chars characters with padding_char, replicated as many times as
necessary.
Parameters:
column: column, formula or function to padnb_chars: length of output stringpadding_char: character to use for padding
Example:
rpad([MyColumn], 4, " ")
split()¶
Splits a string on the specified delimiter and returns the part at the specified position.
Parameters:
column: column, formula or functiondelimiter: delimiter stringpart: position of the portion to return (counting from 1).
Example:
split([MyStringColumn], "/", 2)
Availability: all data source types except Microsoft SQL Server.
substring()¶
Extract a substring from column values.
Parameters:
column: column, formula or functionfirst_char: Index of first char extracted. Starts at 1.nb_chars: Length of extracted substring
Example:
substring([MyStringColumn], 1, 5)
Availability: all data source types.
replace()¶
Replace all occurrences of substring_from with substring_to.
Parameters:
column: column, formula or functionsubstring_from: Substring to replacesubstring_to: New substring
Example:
replace([MyStringColumn], "ABC", "X")
Availability: all data source types.
Conversion functions¶
float()¶
Convert string column values to float values. If the string cannot be converted to a numeric value, the function will return an error.
If your input column contains string which are not representation of float values, you can create a conditional formula
using regexp_match([input_column],"[+-]?([0-9]*[.])?[0-9]+"). If this is true, return float([input_column]) else
return a default value (either null() or 0).
Parameters:
column: column, formula or function
Example:
float([MyStringColumn])
Availability: all datasources except files.
numeric()¶
Convert string column values to numeric values. If the string cannot be converted to a numeric value, the result is 0.
Parameters:
column: column, formula or function
Example:
numeric([MyStringColumn])
Availability: only files.
str()¶
Convert column values to string values.
Parameters:
column: column, formula or function
Example:
str([MyColumn])
Availability: all data source types.
round()¶
Convert column values to their closest integer values. Float values are casted to integer values. Undefined values
are casted to zero. For example, round(3.1) returns 3 and round(3.9) returns 4.
Parameters:
column: column, formula or function
Example:
round([MyColumn])
Availability: all data source types.
to_int()¶
Convert column values to integer values. Float values are casted to integer values. Undefined values are casted to
zero.
to_int floors the value, i.e. it returns the largest integer less than or equal to the input value. Use round if
you need to round a value to the closest integer number.
Returns 0 if the input value is NULL.
Parameters:
column: column, formula or function
Example:
to_int([MyColumn])
Availability: all data source types.
datetime_from_string()¶
Convert a string to a Datetime.
The function will return an error if the passed string does not match the given format in a single row.
If you are not sure about the quality of your data, use the function regexp_match to check the format. And if it
doesn't match for a row, return null() instead of datetime_from_string.
Parameters:
string: column, formula or function.format: the format of the input string to convert. If your datasource is a file, use the Pythonstrftimeformat (see documentation strftime.org). If your datasource is a PostGreSQL table or a Serenytics storage, use the PostGreSQL syntax (see documentation postgresql.org. If your database is a MySQL table, use the MySQL syntax (see documentation dev.mysql.com). If your database is a BigQuery table, use the BigQuery syntax (see documentation cloud.google.com).
Example:
In this example, the input column contains string such as: 2013--01--23 21:17
# for a file
datetime_from_string([date_str], "%Y--%m--%d %H:%M")
# for a PostGreSQL or a Serenytics storage
datetime_from_string([date_str], "YYYY--MM--DD HH24:MI")
# for a MySQL table
datetime_from_string([date_str], "%Y--%m--%d %H:%i")
Availability: All source types except Microsoft SQL Server.
json_extract_path_text()¶
Extract a value within a string representing a JSON. The parameters specify the path to the value. It returns the empty string if the path does not exist in the JSON.
Parameters:
string: column, formula or function.path1: first key of the JSON path[path2]: second key of the JSON path- up to 5 keys
Availability: Only Serenytics Storages, Redshift, PostGreSQL and MySQL.
Example:
# if the value is '{"first_name":"john", "last_name": "doe"}', returns 'john'.
json_extract_path_text([json_str], "fist_name")
# if the value is '{"first_name":"john", "last_name": "doe", "address": {"city" : "paris"}}'
# returns 'paris'.
json_extract_path_text([date_str], "address", "city")
# if the value is '{"first_name":"john", "last_name": "doe", "address": {"city" : "paris"}}'
# returns an empty string.
json_extract_path_text([date_str], "address", "zipcode")
Ranking functions¶
is_first()¶
Return 1 when current value appears for the first time in column, 0 otherwise. Can be used to work with unique
values or remove doublons.
Parameters:
column: column, formula or function
Example:
is_first([MyColumn])
Availability: only files.
ntile()¶
Sort rows according to column, split them in nb_buckets having the same number of rows and return the id of the
bucket each row falls in. First bucket with smallest values has id 1.
Parameters:
column: column, formula or functionnb_buckets: number of buckets
Example:
ntile([MyColumn], 100)
Availability: all data source types.
rank()¶
Sort rows according to column in order (either "asc" or "desc") and return the rows ranking. If several rows have
the same value, they get the same ranking and there will be a discontinuity in the result.
If partition_byis specified, the ranking is computed for each value of this column.
Parameters:
column: column, formula or functionorder: either"asc"or"desc"partition_by[optional]: column, formula or function
Example:
rank([MyColumn], "asc")
# compute the orders rankings, by customer
rank([order_date], "asc", [order_customer_id])
Availability: all data source types.
dense_rank()¶
Sort rows according to column in order (either "asc" or "desc") and return the rows ranking. If several rows have
the same value, they get the same ranking. The dense_rank function differs from rank in one respect: if two or more
rows tie, there is no gap in the sequence of ranked values. For example, if two rows are ranked 1, the next rank is 2.
If partition_byis specified, the ranking is computed for each value of this column.
Parameters:
column: column, formula or functionorder: either"asc"or"desc"partition_by[optional]: column, formula or function
Example:
dense_rank([MyColumn], "desc")
# compute the orders rankings, by customer
rank([order_date], "asc", [order_customer_id])
Availability: all data source types.
Value functions¶
sum()¶
Compute the sum of column.
Parameters:
column: column, formula or function
Example:
sum([MyColumn])
sum_if()¶
Compute the sum of column for rows where condition is true.
Parameters:
column: column, formula or functioncondition: boolean expression
Example:
sum_if([column], [MyOtherColumn] == 3)
avg(), avg_if()¶
Return the average. See sum and sum_if for more details.
min(), min_if()¶
Return the min. See sum and sum_if for more details.
max(), max_if()¶
Return the max. See sum and sum_if for more details.
count(), count_if()¶
Return the number of data rows. See sum and sum_if for more details.
dcount(), dcount_if()¶
Return the distinct count (number of different values). See sum and sum_if for more details.
quantile_if()¶
Return the value from column at the quantile given by fraction, with a condition
Parameters:
column: column, formula or functionfraction: quantile fraction (e.g. 0.5 for the median)interpolation: interpolation method to use when the desired quantile lies between two data points. Choices are:"linear"or"nearest"condition: condition to apply before the computation is done
Example:
# compute median value:
quantile_if([MyColumn], 0.5, "linear", [other_col]=="PROD")
Availability: only files and API.
last_value()¶
Get the last value of value_column when ordering by order_column.
Parameters:
value_column: column, formula or functionorder_column: column, formula or function used to order the values ofvalue_column
Example:
# get the most recent value of a time serie
last_value([value], [date])
last_value_if()¶
Get the last value of value_column for rows where condition is true when ordering by order_column.
Parameters:
value_column: column, formula or functionorder_column: column, formula or function used to order the values ofvalue_columncondition: boolean expression
Example:
# get the last value in the previous month
last_value_if([value], [date], [date] in month(-1))
Data-quality functions¶
is_defined()¶
Returns False if column is NULL or an empty string, otherwise returns True. Use
not is_defined([myCol]) to test if a column is not NULL.
Parameters:
column: column, formula or function
Example:
is_defined([MyColumn])
is_defined() in conditional formula in SQLServer data-sources
In a conditional formula in a SQLServer data-source, you have to use is_defined_sqlserver_condition([MyColumn])
instead of is_defined([MyColumn]).
is_empty()¶
Returns True if column is an empty string, False otherwise. Column must be of type String. Use
not is_empty([myCol]) to test if a column is not empty.
Parameters:
column: column, formula or function
Example:
is_empty([MyColumn])
Misc¶
null()¶
Returns the NULL value.
This can be used when you need to dcount values of a column, but you want to exclude some rows. You can create a
conditional formula that will return null() for the rows to exclude. And then, apply your dcount on this conditional
formula. The null rows won't be counted in the dcount.
To check if a column is NULL or empty, it's simpler to use the functions is_defined or is_empty.
Example:
Using a table with a list of purchases, you can count the distinct number of customers who has bought items with a
price higher than 100 doing a dcount on the below formula. This will also work if you group the purchases by any
dimensions (e.g. grouping by the category of products in a table widget).
IF [price]>100 THEN [client_id]
ELSE null()